 geralt
geralt
Facebook открыла исходный код PyText, библиотеки для обработки устной и письменной речи. По мнению разработчиков, такой шаг должен ускорить развитие проекта.
Сфера применения PyText
NLP-библиотека (Natural Language Processing — обработка естественной речи) используется в используется в нейросетях для обработки письменной и устной речи. По словам разработчиков, инструмент полезен для классификации документов, разметки речевых последовательностей, семантического анализа и многозадачного моделирования.
 Вам будет интересно:В Госдуму внесли законопроект об автономной работе Рунета
Вам будет интересно:В Госдуму внесли законопроект об автономной работе Рунета
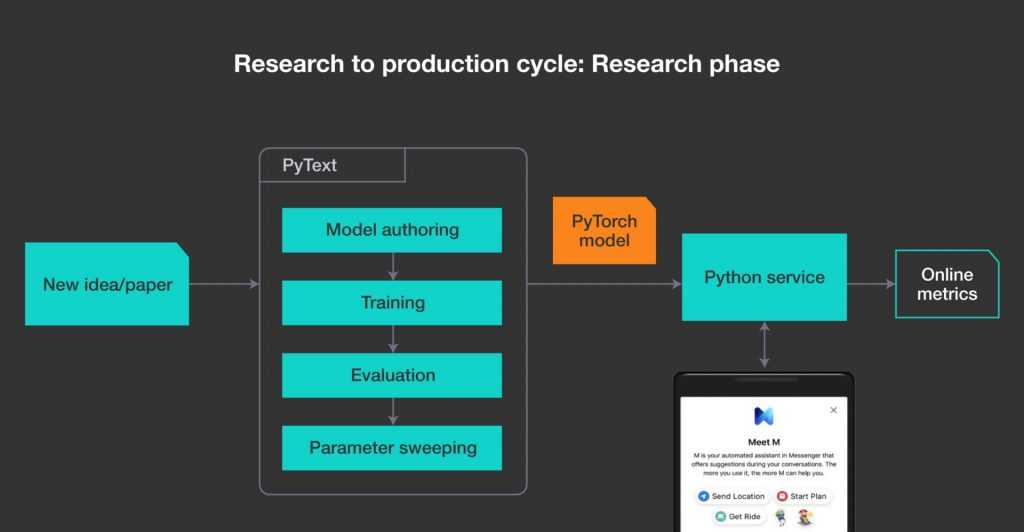
Структура библиотеки позволяет легко перейти от разработки NLP-системы к практическому применению. Инженеры компании утверждают, что с использованием PyText реализация модели нейросети, распознающей человеческую речь, займёт всего несколько дней.
Особенности библиотеки
- PyText основана на PyTorch, фреймворке с развитой экосистемой, поэтому модели, созданные с помощью NLP-библиотеки, легко публиковать.
- В состав инструмента входит несколько уже готовых моделей. Структура PyText позволяет модифицировать их с небольшими трудозатратами, что упрощает разработку.
- Разработчики включили в библиотеку специальные модели, использующие контекст речи для лучшего распознавания сути высказываний. Они протестированы на датасетах с помощью инструмента M Suggestions (одна из функций помощника) в Facebook Messenger.
- PyText может проводить распределённое обучение, а также работать с несколькими моделями одновременно.
- Интеграция с фреймворком PyTorch позволяет библиотеке конвертировать модели в ONNX и использовать движок Caffe2 для их экспорта.
- Масштабирование собственных моделей в PyTorch ограниченно из-за лимита многопоточности принципа Global Interpreter Lock в Python.
- Экспортированные модели позволяют использовать возможности C++ для повышения производительности.
Компания уже применяет PyText на практике. По словам разработчиков, созданные с её помощью модели ежедневно делают более миллиарда прогнозов на Facebook. Открытие исходного кода и свободная лицензия должны привлечь к совершенствованию инструмента независимых специалистов. При этом инженеры компании не устраняются от дальнейшей разработки системы. Они намерены сконцентрировать усилия на использовании её возможностей в сфере мобильных устройств.
Исходный код инструмента размещён в репозитории GitHub. Лежащая в основе NLP-библиотеки стабильная версия фреймворка PyTorch 1.0 вышла в декабре 2018 года.